一、索引算法简介
1.1 B+Tree
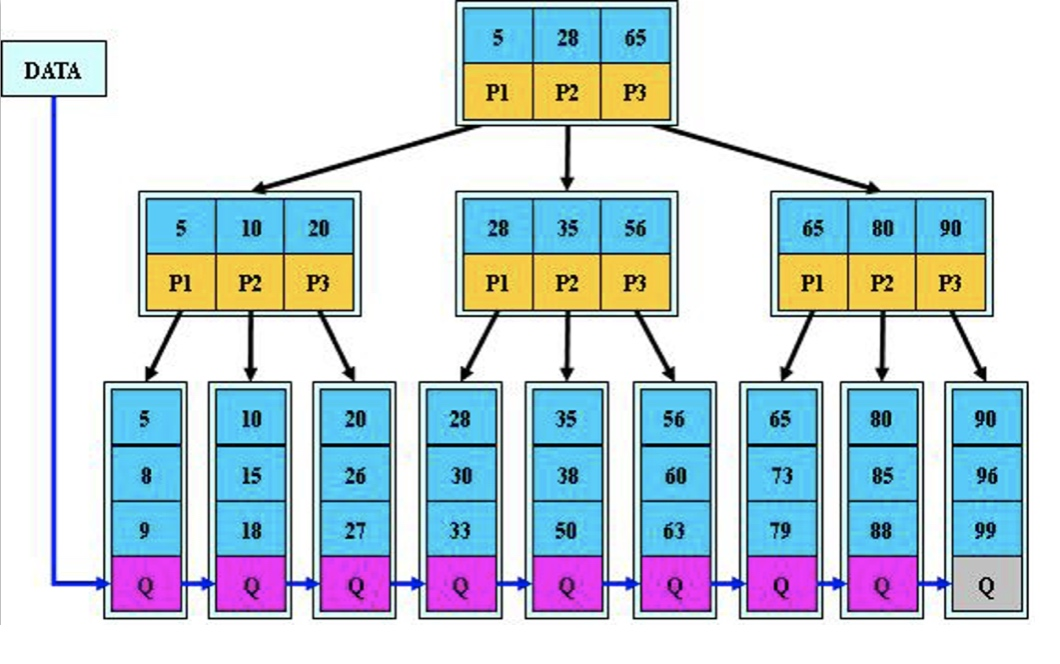
1.2 B*Tree

二、索引管理
2.1 基础概念
索引建立在表的列上(字段)的。
在where后面的列建立索引才会加快查询速度。
pages<---索引(属性)<----查数据。
2.2 索引分类
主键索引
普通索引*****
唯一索引
2.3 索引创建
#创建普通索引
mysql> alter table student1 add index idx_id(id);
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
#创建主键索引
mysql> alter table student1 add primary key pri_name(name);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
#创建唯一索引
mysql> alter table student1 add unique key uni_age(age);
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
#查看索引
mysql> show index from student1;
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type |Comment | Index_comment |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student1 | 0 | PRIMARY | 1 | name | A | 0 | NULL | NULL | | BTREE | | |
| student1 | 0 | uni_age | 1 | age | A | 0 | NULL | NULL | YES | BTREE | | |
| student1 | 1 | idx_id | 1 | id | A | 0 | NULL | NULL | YES | BTREE | | |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
3 rows in set (0.00 sec)
#删除索引
mysql> alter table student1 drop key idx_id;
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
#添加前缀索引
mysql> alter table student1 add index idx_name(name(4));
Query OK, 0 rows affected (0.01 sec)
Records: 0 Duplicates: 0 Warnings: 0
#创建联合索引
mysql> alter table student1 add index idx_all(id,name,age,sex);
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
mysql> show index from student1;
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| Table | Non_unique | Key_name | Seq_in_index | Column_name | Collation | Cardinality | Sub_part | Packed | Null | Index_type |Comment | Index_comment |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
| student1 | 1 | idx_all | 1 | id | A | 0 | NULL | NULL | YES | BTREE | | |
| student1 | 1 | idx_all | 2 | name | A | 0 | NULL | NULL | | BTREE | | |
| student1 | 1 | idx_all | 3 | age | A | 0 | NULL | NULL | YES | BTREE | | |
| student1 | 1 | idx_all | 4 | sex | A | 0 | NULL | NULL | YES | BTREE | | |
+----------+------------+----------+--------------+-------------+-----------+-------------+----------+--------+------+------------+---------+---------------+
4 rows in set (0.00 sec)
#注 联合索引主要针对多条件查询,因此需要把最常用的条件放到最前面 规则遵循前缀生效特性
2.4 索引创建规则
- 创建唯一索引
- 如果该列重复值较多,采用联合索引
- 经常需要排序、分组和联合操作的字段建立索引
- 常作为查询条件的字段建立索引
- 索引字段的值很长,尽量使用前缀索引
- 限制索引数目
- 删除不再使用或者很少使用的素引
2.5 索引优化规则
没有查询条件,或者查询条件没有索引。
- a)添加查询条件。
- b)为查询条件创建素引
查询结果集是原表中的大部分数据,应该是25%以上不走索引a)使用limit去查询数据
索引本身损坏(失效),不走索引
- a)监控索引
- b)删除索引,重新建立素引
使用函数在索引列上或者对索引列进行运算,不走索引
隐式转换导致索引失效
<>,not in 不走索引
like%”百分号在最前面不走索引
单独引用联合索引里非第一位置的索引列.
三、Explain使用
3.1 Explain详解
#命令常见使用方法
mysql> explain select name,countrycode from city where id=1;
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | city | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
各字段含义
- id: select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
- select_type: 查询的类型,主要是用于区别,普通查询、联合查询、子查询等的复杂查询(SIMPLE,PRIMARY,DERIVED,SUBQUERY,DEPENDENT SUBQUERY,UNCACHEABLE SUBQUREY等)
- table:显示这一行的数据是关于哪张表的
- type:type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是: system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range(尽量保证) > index > ALL。一般来说,得保证查询至少达到range级别,最好能达到ref。
- possible_keys:显示可能应用在这张表中的索引,一个或多个。查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
- key:实际使用的索引。如果为NULL,则没有使用索引
- key_len:表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。
- ref:显示索引的哪一列被使用了,如果可能的话,是一个常数。哪些列或常量被用于查找索引列上的值
- rows:rows列显示MySQL认为它执行查询时必须检查的行数。(越少越好)
- Extra:包含不适合在其他列中显示但十分重要的额外信息
- Using filesort
说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。 - Using temporary
使了用临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序 order by 和分组查询 group by。 - USING index
表示相应的select操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错! - Using where
表明使用了where过滤 - using join buffer
使用了连接缓存: - impossible where
where子句的值总是false,不能用来获取任何元组 - select tables optimized away
在没有GROUPBY子句的情况下,基于索引优化MIN/MAX操作或者
- Using filesort
3.2 Type字段分析
- ALL:全表扫描
mysql> explain select * from city;
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| 1 | SIMPLE | city | ALL | NULL | NULL | NULL | NULL | 4188 | NULL |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
1 row in set (0.00 sec)
- index:Full Index Scan,index与ALL区别为index类型只遍历索引树。
mysql> explain select countrycode from city ;
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-------------+
| 1 | SIMPLE | city | index | NULL | CountryCode | 3 | NULL | 4188 | Using index |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-------------+
1 row in set (0.00 sec)
- range:索引范围扫描,对索引的扫描开始于某一点,返回匹配值域的行。显而易见的索引范围扫描是带有between或者where子句里带有<,>查询
mysql> explain select * from city where countrycode in ('CHN','USA');
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-----------------------+
| 1 | SIMPLE | city | range | CountryCode | CountryCode | 3 | NULL | 637 | Using index condition |
+----+-------------+-------+-------+---------------+-------------+---------+------+------+-----------------------+
1 row in set (0.00 sec)
- ref:使用非唯一索引扫描或者唯一索引的前缀扫描,返回匹配某个单独值的记录行。
mysql> explain select * from city where countrycode='CHN';
+----+-------------+-------+------+---------------+-------------+---------+-------+------+-----------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+-------------+---------+-------+------+-----------------------+
| 1 | SIMPLE | city | ref | CountryCode | CountryCode | 3 | const | 363 | Using index condition |
+----+-------------+-------+------+---------------+-------------+---------+-------+------+-----------------------+
1 row in set (0.00 sec)
- eq_ref:类似ref,区别就在使用的索引是唯一索引,对于每个索引键值,表中只有一条记录匹配,简单来说,就是多表连接中使用primary key或者 unique key作为关联条件A
- const、system:当MySQL对查询某部分进行优化,并转换为一个常量时,使用这些类型访问。
mysql> explain select * from city where id=1000;
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
| 1 | SIMPLE | city | const | PRIMARY | PRIMARY | 4 | const | 1 | NULL |
+----+-------------+-------+-------+---------------+---------+---------+-------+------+-------+
1 row in set (0.00 sec)
- NULL:MySQL在优化过程中分解语句,执行时甚至不用访问表或索引,例如从一个索引列里选取最小值可以通过单独索引查找完成。
mysql> explain select * from city where id=10000000000000000000000000;
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+
| 1 | SIMPLE | NULL | NULL | NULL | NULL | NULL | NULL | NULL | Impossible WHERE noticed after reading const tables |
+----+-------------+-------+------+---------------+------+---------+------+------+-----------------------------------------------------+
1 row in set (0.00 sec)
转载:drz



