1.简介
Prometheus发出告警时分为两部分。首先,Prometheus按告警规则(rule_files配置块)向Alertmanager发送告警(即告警规则是在Prometheus上定义的)。然后,由Alertmanager来管理这些告警,包括去重(Deduplicating)、分组(Grouping)、静音(silencing)、抑制(inhibition)、聚合(aggregation ),最终将面要发出的告警通过电子邮件、webhook等方式将告警通知路由(route)给对应的联系人
2.安装Alertmanager
wget http://github.com/prometheus/alertmanager/releases/download/v0.20.0/alertmanager-0.20.0.linux-amd64.tar.gz
tar -xvf alertmanager-0.20.0.linux-amd64.tar.gz
mv alertmanager-0.20.0.linux-amd64 /usr/local/alertmanager
3.编辑配置文件
配置文件路径/usr/local/alertmanager/alertmanager.yml
配置如下
global: #全局配置
resolve_timeout: 5m
smtp_smarthost: 'smtp.163.com:465' #smtp服务器的地址 我这里使用的是163的
smtp_from: 'liyonghui_1997@163.com' #发送邮件使用的邮箱
smtp_auth_username: 'liyonghui_1997@163.com' #用于发送邮件时登录邮箱服务器的邮箱地址
smtp_auth_password: 'DRHMxxxxxxxxx' #邮箱授权码 可以在163的邮箱设置中获取
smtp_require_tls: false
templates:
- '/usr/local/alertmanager/template/default.tmpl' #发送邮件的模板 不需要的话可以不配置的 但是Alertmanager默认模板告警项不直观 且时间是UTC时间查看不方便
route: #默认路由规则
group_by: ['alertname']
group_wait: 30s #组等待同组告警默认等待30s
group_interval: 1m #当一个新的告警组被创建时,需要等待'group_wait'后才发送初始通知。这样可以确保在发送等待前能聚合更多具有相同标签的告警,最后合并为一个通知发送
repeat_interval: 5m #告警发送间隔时间
receiver: 'mail'
receivers:
- name: 'mail' #发送方式
email_configs: #接受方的邮箱
- to: 'www.2668416023@foxmail.com'
send_resolved: true #是否发送恢复告警
html: '{{ template "default.html" . }}' #模板的配置规则 如果不想配置的这里可以忽略
headers: { Subject: "{{ .GroupLabels.SortedPairs.Values }} [{{ .Status | toUpper }}:{{ .Alerts.Firing | len }}]" }
inhibit_rules: #告警抑制规则
- source_match:
severity: 'critical'
target_match:
severity: 'warning'
equal: ['alertname', 'dev', 'instance']
模板配置
路径/usr/local/alertmanager/template/default.tmpl
{{ define "default.html" }}
{{- if gt (len .Alerts.Firing) 0 -}}
[{{ .Status | toUpper }}:{{ .Alerts.Firing | len }}]
{{ range $i, $alert := .Alerts }}
<pre>
告警节点:{{ index $alert.Labels "instance" }}
告警服务:{{ index $alert.Labels "alertname" }}
报警详情:{{ index $alert.Annotations "summary" }}
开始时间:{{ $alert.StartsAt.Local }}
</pre>
{{ end }}
{{ end }}
{{- if gt (len .Alerts.Resolved) 0 -}}
[{{ .Status | toUpper }}:{{ .Alerts.Resolved | len }}]
{{ range $i, $alert := .Alerts }}
<pre>
恢复节点:{{ index $alert.Labels "instance" }}
恢复服务:{{ index $alert.Labels "alertname" }}
状 ? ?态:{{ index $alert.Status }}
开始时间:{{ $alert.StartsAt.Local }}
恢复时间:{{ $alert.EndsAt.Local }}
</pre>
{{ end }}
{{ end }}
{{- end }}
配置完成后可以使用自带的工具检查下格式
./amtool check-config alertmanager.yml
Checking 'alertmanager.yml' SUCCESS
Found:
- global config
- route
- 1 inhibit rules
- 1 receivers
- 1 templates
SUCCESS
4.启动
我是使用的nohup启动的 也可以使用systemctl来启动
nohup /usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/usr/local/alertmanager/data --web.listen-address=0.0.0.0:9093 --data.retention=120h>> /usr/local/alertmanager/logs/alertmanager.log 2>&1 &
查看进程是否正常运行
ps -ef | grep aler
root 16687 30885 0 15:08 pts/1 00:00:00 grep --color=auto aler
root 30680 1 0 13:16 ? 00:00:05 /usr/local/alertmanager/alertmanager --config.file=/usr/local/alertmanager/alertmanager.yml --storage.path=/usr/local/alertmanager/data --web.listen-address=0.0.0.0:9093 --data.retention=120h
5.prometheus添加配置
alerting:
alertmanagers:
- static_configs:
- targets:
- '118.193.x.x:9093' #Alertmanager节点
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "rules/*_rules.yml" #告警规则配置文件
- "rules/*_alerts.yml"
- job_name: 'alertmanager'
static_configs:
- targets: ['118.193.37.64:9093']
重载配置
kill -HUP 18892
配置没问题的话 就可以在prometheus界面看到Alertmanager
6.配置告警规则
分为两个文件:node_alerts.yml这个主要配置告警的阈值和发送的文本node_rules.yml主要配置告警的规则
配置如下node_rules.yml
groups:
- name: node_rules
rules:
- record: instance:node_cpu_usage
expr: 100 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) * 100
labels:
metric_type: CPU_monitor
- record: instance:node_1m_load
expr: node_load1
labels:
metric_yepe: load1m_monitor
- record: instance:node_mem_usage
expr: 100 - (node_memory_MemAvailable_bytes)/(node_memory_MemTotal_bytes) * 100
labels:
metric_type: Memory_monitor
- record: instance:node_root_partition_predit
expr: node_filesystem_free_bytes{device="/dev/vda1", mountpoint="/"}/(1024*1024*1024)
labels:
metric_type: root_partition_monitor
node_alerts.yml
groups:
- name: node_alerts
rules:
- alert: CPU使用率
expr: instance:node_cpu_usage > 80
for: 1m
labels:
severity: warning
annotations:
summary: 主机 {{ $labels.instance }} 的 CPU使用率持续1分钟超出阈值,当前为 {{humanize $value}} %
- alert: 系统一分钟负载
expr: instance:node_1m_load > 20
for: 1m
labels:
severity: warning
annotations:
summary: 主机 {{ $labels.instance }} 的 1分负载超出阈值,当前为 {{humanize $value}}
- alert: 内存使用率
expr: instance:node_mem_usage > 80
for: 1m
annotations:
summary: 主机 {{ $labels.instance }} 的 内存 使用率持续1分钟超出阈值,当前为 {{humanize $value}} %
- alert: 系统盘磁盘使用
expr: instance:node_root_partition_predit < 10
for: 1m
annotations:
summary: 主机 {{ $labels.instance }} 的 根分区 剩余可用空间只有 {{humanize $value}}GB,,请及时扩容和清理空间!!!!!
配置完成重载kill -HUP 18892
访问prometheus界面即可查看配置的规则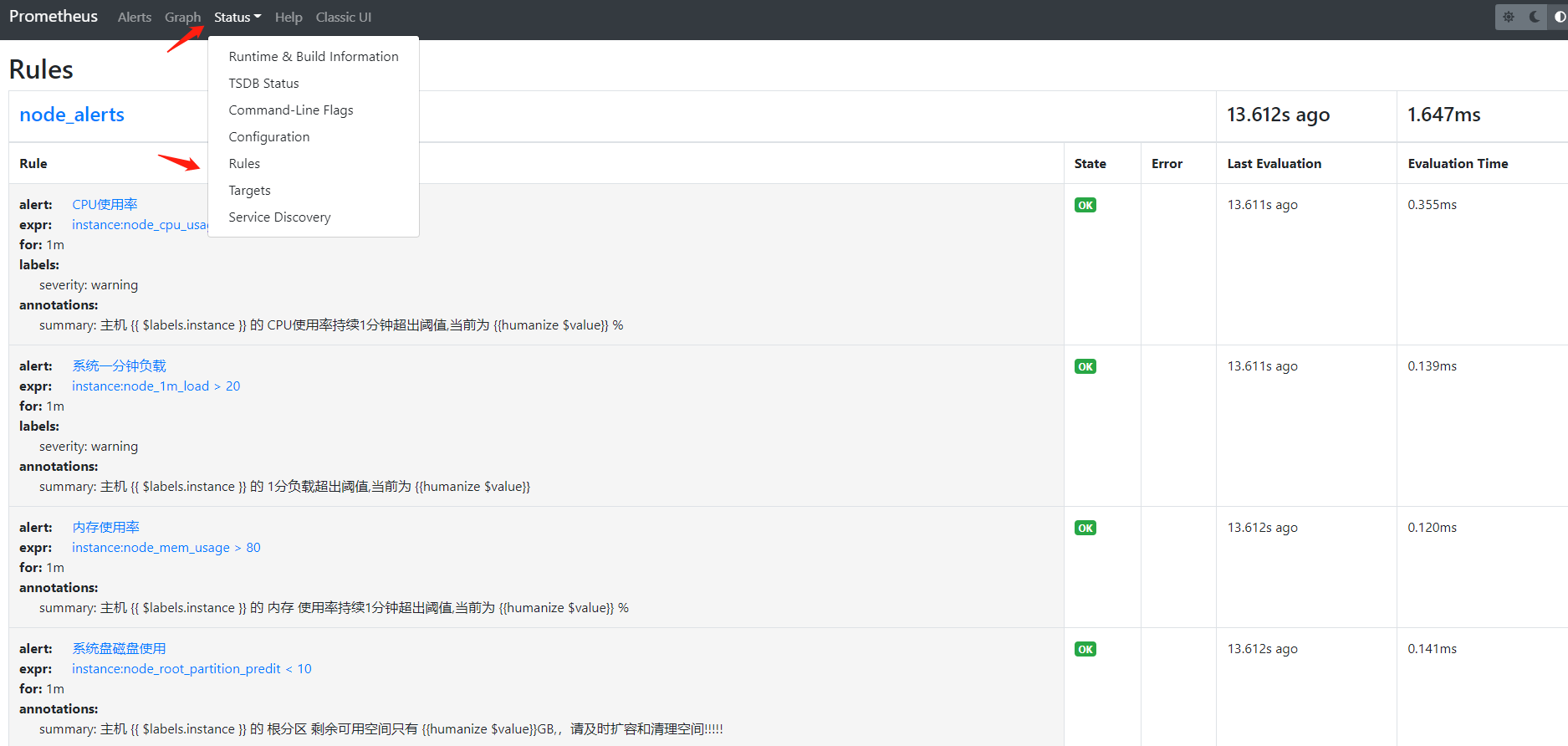
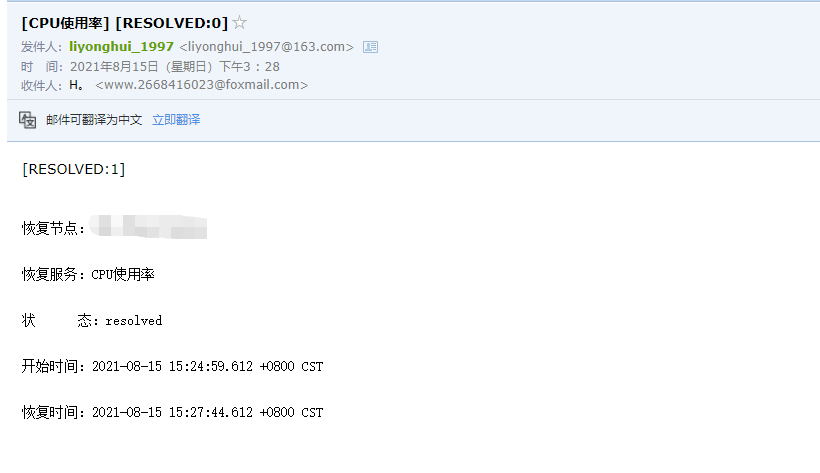
告警的状态
7.测试
压测cpu看下是否可以正常收到告警
stress -c 2 -t 100000
prometheus查看告警规则已经变为pending状态 证明已经检测到这个告警
根据配置一分钟会如果没有恢复会变为firing状态
稍等三十秒即可收到告警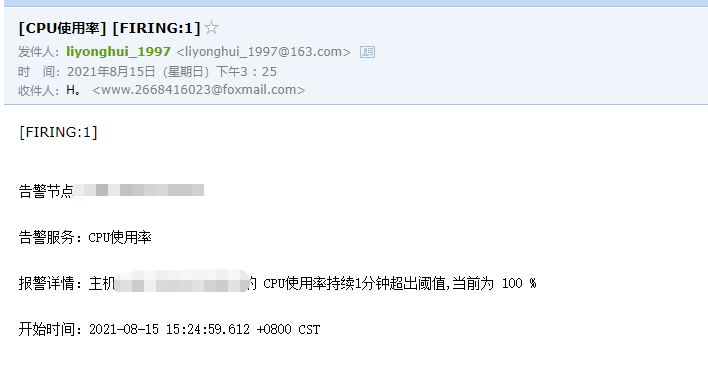
取消压测稍后会收到恢复告警